传统的洛基模型在分析追踪数据时的主要误导,源自所谓“静者―动者”之间的对立,或说是异质性因素。在一项有先驱意义的研究中,Blumen, Kogan 和McCarthy(1955)发现,“典型的个人”从一项职业转移到另一项职业的条件概率,随着他/她在这行所呆时间的增长而递减。他们同时发现过去换职业更多的人,将来换职业的概率也更高。对这种现象的一种解释是,人口构成具有异质性,某一部分人的改行倾向一直高于其他人。也就是说,有些人是“动者”,而另外一些人是“静者”。随着时间的推移,留在某项职业中的静者比率会越来越高。这样,一个群体留在某个特定职业中的条件概率会越来越高,即使每个个体的改行倾向保持不变。这种现象还出现在如下的数据当中:每月的怀孕概率,婚姻的不稳定因素,地域流动性,以及其他的序列质反应。
洛基模型可能会对质反应的横截面数据适用,但是却比较不适合用来分析有异质构成的质反应跟踪数据。我们下面将证明:这种弱点的原因在于它无法提供描绘个体间概率分布的那些高阶矩;而在异质性假设下,正是那些描述个体反应概率分布的高阶矩,决定了我们所观测到的序列反应模式。
在本篇论文里面,我们将改进传统的洛基模型,使之适用于异质构成的质反应跟踪数据,并将之用于描述已婚妇女从业状况的序列数据。
我们对这项应用的兴趣来源于Ben-Porath(1973)的发现,他注意到,凡是基于横截面数据的从业函数都无法对终身从业的现象给出明确的解释,因为一个样本均值不给出分布的高阶矩信息。考虑这样一个例子:我们发现一组已婚妇女的平均年度从业率是50%。 一种极端的解释是,这是一个完全同质性的人群,每个妇女在任何一个年度的从业几率都是50%。在另一个极端,我们的解释是一半妇女永远都工作,而另一半妇女永远都不工作。在第一种情况下,每个妇女把一半的婚后岁月花费在社会的就业队伍里,另一半花费在就业队伍外,而平均一个工作的长度为两年。在第二种情况下没有轮换上岗的现象,每人本阶段的状态是对未来状态的完美预测。当然,在这两者之间,有无穷多个处在中间状态的可能解释。
除此之外,这两种极端的状态也在其他的生活周期当中反应出来。举个例子,在同质性的例子里面,已婚妇女和她们的雇主相对来说不太愿意在女性雇员的人力资本上投资,不管是广义还是具体的培训,而只有妇女的总体从业率上升才能提高雇主的培训意向。而在异质性的例子里面,雇主就比较愿意在女雇员身上投资,因为她们的工作稳定性大。换言之,通过对时间横截面数据的那种传统分析,对于异质性群体中的个人来说,不一定有意义。
我们将从一个简单的序列从业模型开始,证明如果有未观测到的长时间因素影响从业概率,那么个体妇女之间就将出现异质性,并讨论这种异质性的含义和影响。然后,我们假设从业概率服从贝塔分布,通过对贝塔分布的参数化,推导出一个关于序列从业行为的似然函数,并可还原到传统的横截面洛基模型。因此,我们把自己的这个模型叫做“贝塔--逻辑斯谛模型”,将其应用到对一组实证从业数据的分析上,并对参数估计的含义和模型的不足作讨论。
......
对付异质性的办法之一是假设一个关于从业概率的分布函数,然后从跟踪数据集出发,对其参数进行估计。贝塔分布的函数如下
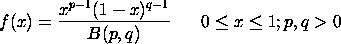
其中

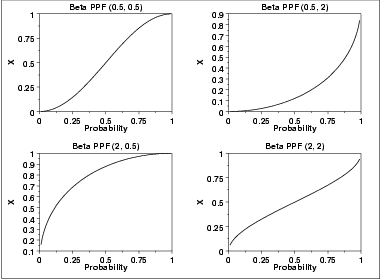
作为一种概率密度函数,贝塔函数有很多优点:首先是Beta值域落在(0,1)之间;其次,这个分布仅有两个参数;再次,它的分布形状可以十分灵活:如果alpha>1, beta>1,则是单峰分布;如果alpha, beta<1,则是U形分布;如果两者都等于1,则是均匀分布;如果其中一个大于等于1,另外一个小于1,则是J形分布。这样,我们假设f(pie)近似一个贝塔分布。
在这个年度从业概率服从贝塔分布的假设下,我们现在来推导任何从业路径的期望概率。在N年的时段里面工作了j年的期望概率可以通过下式求积分得到:
(n取j的组合) 乘 (从业概率^j) 乘 (不从业概率^k) 乘 (从业概率分布函数)
从这个函数可以推导出来这样一个结果:在阶段t, t-1阶段工作过的人和没工作的人之间有一个条件概率的差值:
(a+1)/(a+b+1)
-a/(a+b+1)
__________________________
1/(a+b+1)
当a,b趋向于正无穷,这个差值趋向于零,也就是彻底的同质性。在已婚妇女从业的例子里面,也就是
当a,b趋向于零,这个差值趋向于1,也就是绝对的异质性。
......
将a,b这两个参数设为两个外生变量集x的函数,即为
a=e^(X'alpha)
b=e^(X'beta)
这样保证了a b的非负性。
根据期望概率方程,我们可以把在任何一个年度的平均工作概率写成
E[p(1,1)]=a/(a+b)=1/(1+e^(-X'(alpha-beta))
注意,这就是一个典型的洛基函数,它的向量是gamma=alpha-beta。如果我们只有横截面数据,我们就无法分别估计alpha和beta。 所以,一般的洛基函数只能用来根据X值预报某个群体平均就业概率,但却不能用来确定从业概率分布的高阶矩。然而,一组包括两个时期(及以上)的跟踪数据就能帮我们分别确定alpha和beta值。
下面我们用这个贝塔-逻辑斯蒂模型来分析密歇根大学做的1968-1972年收入跟踪数据。样本包括了1583位在67-71年内未有婚变的家庭妇女。我们通过问每个妇女的丈夫“去年你的妻子是否有上班?”,得到因变量和其他一些自变量的原始数据,由此得到最大似然估计。